
title
sub_title

신흥국의 AI 도입 가속: 글로벌 AI 혁신의 시작

모두의창업 솔루션 - 번지는 경쟁사 실제 데이터까지
투자자와 심사위원이 공통으로 하는 질문이 있습니다경쟁사가 얼마나 성장하고 있나요사용자들이 경쟁 서비스에서 불만을 느끼는 부분이 뭔가요이 질문에 감이 아니라 데이터로 답할 수 있어야 합니다Bunzee가 경쟁사 데이터를 어떻게 꺼내는지 보여드립니다httpswwwmodooorkraisolutionorganization578tabsolutionBunzee번지는 아이디어를 말로만 설명하는 것이 아니라 이 시장에는 이런 경쟁사가 있고 우리는 이런 차별화 전략으로 이런 제품 프름을 만들겠습니다 라고 시장 근거와 화면 흐름을 보여줄 수 있습니다필요한 경우 MCP를 통해 Claude Code Lovable 등 코딩 AI와 연결해 목업 이후의 MVP 개발 출발점까지 이어갈 수 있습니다 Bunzeeai는 모두의 창업 도전자들이 감이 아니라 데이터로 아이디어를 검증하고 다음 라운드에서 설명 가능한 사업 구조와 제품 방향을 준비할 수 있도록 돕는 데이터 기반 아이디어 검증 AI 솔루션입니다0 경쟁사 실제 수치 — 월 트래픽과 매출을 직접 확인경쟁사 리스트가 나타나면 각 서비스를 선택해 실제 지표를 확인할 수 있습니다월 활성 사용자MAU 이 서비스에 실제로 몇 명이 오는가추정 매출Revenue 이 서비스가 월에 얼마를 버는가성장 추이 최근 트래픽이 오르고 있는가 내려가고 있는가예를 들어 동네 식재료 나눔 앱 아이디어를 분석하면 OLIO의 월 활성 사용자 12M 추정 매출 99K 성장률 18 같은 숫자가 나옵니다이 숫자들이 시장이 실제로 성장하고 있는지 내가 진입할 타이밍인지를 알려줍니다 Bunzee 통합리포트 마케팅 키워드 강점 약점 핵심기능 업데이트 히스토리 스크린샷 주요지표 월간UU 월간 PV 평균 체류시간 월간 수익 사용자 피드백 분석 장점 단점 오디언스 상위 국가 성별 연령분포 디바이스 트래픽 소스 Direct Organic Search Referral Organic Social가 제공됩니다1 기능 분석 — 경쟁사가 무엇을 하고 있는가트래픽 숫자 다음으로 중요한 건 기능 구성입니다Bunzee는 각 경쟁사의 핵심 기능을 자동으로 분석해 정리합니다 핵심 기능 목록 가격 정책 타겟 고객 세그먼트이 분석을 보면 경쟁사가 잘 하는 것과 못 하는 것이 구분됩니다경쟁사가 못 하는 부분이 내 아이디어의 포지션이 됩니다2 리뷰 분석 — 사용자가 실제로 불편한 것가장 중요한 데이터는 실제 사용자 리뷰입니다긍정 리뷰보다 부정 리뷰가 더 중요합니다 부정 리뷰 안에 내 아이디어의 포지션이 있기 때문입니다Bunzee는 경쟁사의 App Store Google Play Trustpilot 리뷰를 분석해 주요 불만을 자동으로 정리합니다기록은 쉬운데 기록된 내용이 어디에 쓰이는지 보여주지 않음캘린더와 일기 데이터가 따로 놀아 맥락 파악이 어려움이런 불만들이 내 아이디어의 차별화 방향이 됩니다3 전체 시장 리포트 — TAM·SAM·SOM 자동 산출개별 경쟁사 분석이 끝나면 Bunzee는 전체 시장 리포트를 자동으로 만듭니다 TAM 전체 시장 이 시장의 총 규모SAM 유효 시장 내가 실제로 공략 가능한 규모SOM 획득 가능 시장 현실적으로 내가 가져올 수 있는 규모이 숫자들이 투자자 IR 자료와 2라운드 발표 자료의 시장 규모 파트를 바로 채웁니다모두의 창업 AI 솔루션 비교는 여기서 → httpsbunzeeaimodooanalysis모두의창업 솔루션 신청은 → httpswwwmodooorkraisolutionorganization578tabsolution
모두의 창업 성공 아이디어 탐색 및 분석기 공개
모두의 창업 2차 준비하시는 분들 계시죠1차에서는 어떻게 써야 할지 모르시는 분들이 많았지만 2차에서는 1차라는 모범답안들이 있습니다물론 베끼라는 말은 아니지만 그래도 참고할만한 데이터가 있으면 더 좋지않을까요모두의 창업 AI 솔루션으로 더 유명한 번지Bunzee에서 출시한 모두의 창업 아이디어 분석 서비스입니다궁금하신 분은 여기 클릭하면 더 보실 수 있어요httpswwwmodooorkraisolutionorganization578tabsolution아래 주소로 들어가시면 아래와 같이 여러가지 필터를 걸어서 조회하실 수 있습니다httpsbunzeeaimodooanalysis일반테크 기반으로 선택하시거나 로컬기반으로 선택하셔도 되고 자유롭게 탐색하실수 있는데요모두의 창업 보시는것과 다른것은 크게 세가지 정도 되는것 같아요1 일단 화면이 상세로 넘어가지 않는다모두의 창업에서는 상세화면에서만 아이디어를 볼 수 있는데 이 서비스에서는 바로 내용을 팝업처럼 확인할 수 있습니다2 키워드를 여러개로 조회할 수 있다모두의 창업에서는 키워드 하나만 조회가 가능한데 여러가지 키워드를 or 조건으로 검색해볼 수 있고키워드 걸린 순서대로 정렬이 되니까 여러가지 키워드를 넣어볼 수 있습니다어디서 키워드가 걸린건지 몇개가 걸린것인지 알 수 있습니다3 아이디어를 서로 비교할 수 있습니다단순히 검색이나 조회를 넘어서 아이디어를 1대1로 비교할 수 있습니다실제 원문을 기반으로 해서 어떠한 문제점과 타겟 그리고 솔루션으로 접근하고 있는지 분해가 가능해요개 꿀팁이죠 헤메지 말고 어떤게 합격했는지 보고 2차 준비하세요
멀티모달 AI의 기술적 이해와 월드모델
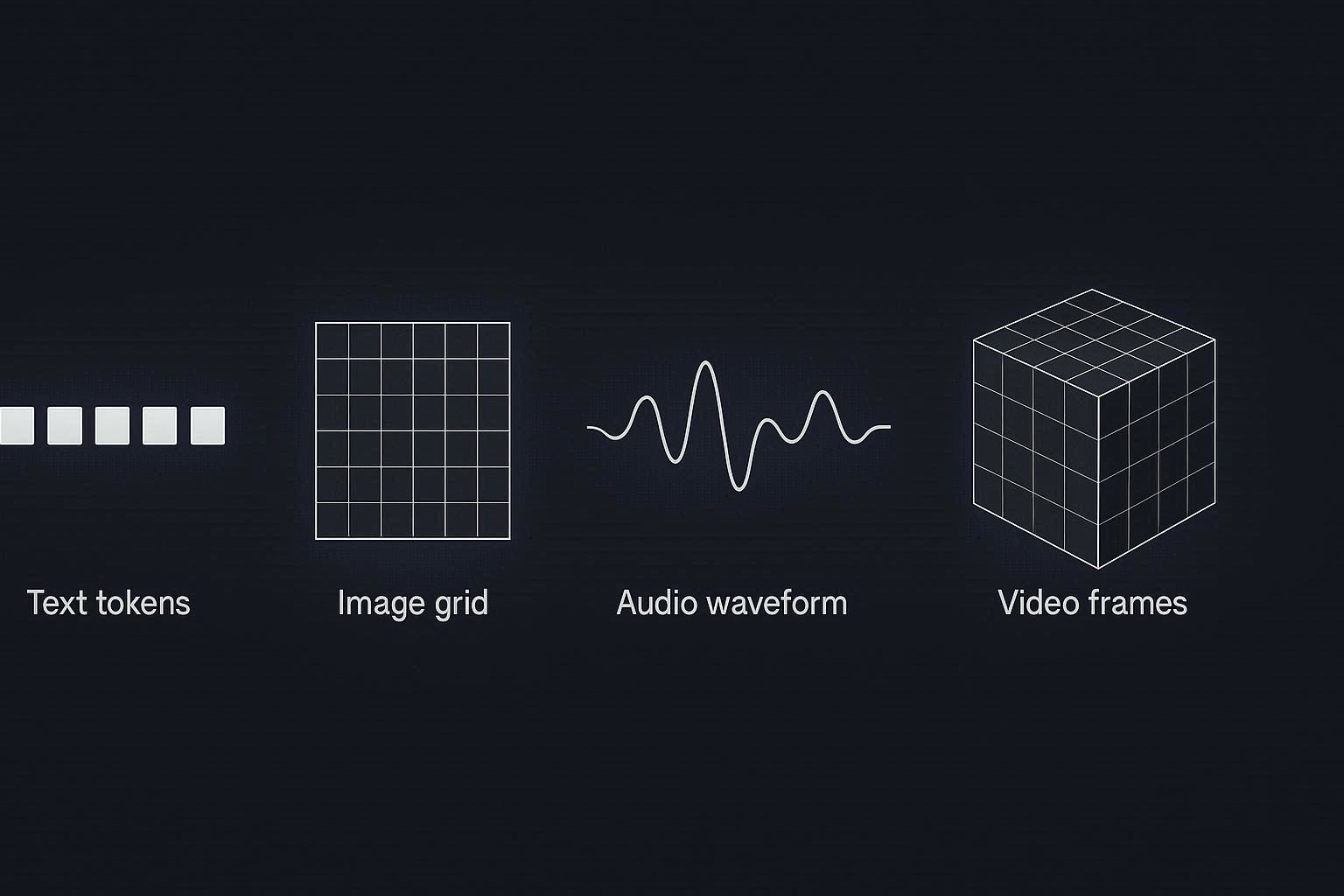
모달리티는 ‘데이터 형식’이 아니라 ‘정보 표현 체계’다텍스트 이미지 음성은 단순히 형식이 다를 뿐이 아니다이들은 정보를 인코딩하는 방식 자체가 다르다 텍스트 → 이산적discrete 토큰 시퀀스 이미지 → 연속적continuous 공간 신호 2D spatial grid 음성 → 시간 기반 연속 신호 1D temporal wave 영상 → 시간 공간 결합 신호 3D spatiotemporal tensor즉 문제의 본질은 이거다서로 다른 통계 구조를 가진 신호를 하나의 계산 구조 안에서 다루는 것멀티모달의 핵심 난제는 “합치는 것”이 아니라 이질적 통계 구조를 정렬하는 것이다공통 임베딩 공간은 왜 가능한가모든 현대 멀티모달 시스템의 기초는 Representation Learning이다각 모달은 고유한 인코더를 가진다 Text Encoder Transformer 기반 Vision Encoder ViT CNN Patchbased Transformer Audio Encoder Spectrogram Transformer이 인코더의 목표는 단 하나다고차원 신호를 의미 중심의 벡터 표현으로 압축하는 것그리고 이 벡터들을 같은 벡터 공간에 배치한다 이때 핵심 개념이 바로 Joint Embedding Space수학적으로 보면 각 모달 인코더는 함수다 ftextxtext → ℝd fimageximage → ℝd faudioxaudio → ℝd출력 차원 d를 동일하게 맞춘다그 다음 학습 목표는의미적으로 같은 샘플 쌍은 벡터 거리를 가깝게 다른 샘플은 멀어지게이를 위해 Contrastive Learning이 주로 사용된다이 과정을 통해 모달 간 의미 정렬이 일어난다CrossModal Alignment의 수학적 직관이 구조가 안정화되면 이런 현상이 발생한다 텍스트로 이미지 검색 가능 이미지로 텍스트 생성 가능 공통 의미 기반 추론 가능즉 모달은 달라도 의미 표현은 공유된다이게 멀티모달의 1차 진화다Early Late Hybrid Fusion을 더 기술적으로 보자1 Late Fusion 독립 표현 후결합구조각 모달 → 독립 인코딩 → 고수준 표현 벡터 생성 → Fully connected layer에서 결합문제모달 간 저수준 상호작용이 없다 고차원 의미 통합이 제한적이다이 구조는 “결과 통합”이지 “표현 통합”이 아니다2 Early Fusion 입력 수준 통합모든 입력을 하나의 시퀀스로 변환한다예 이미지 → 패치 토큰화 텍스트 → 토큰화 오디오 → 프레임 토큰화그리고 하나의 Transformer에 넣는다이 경우모달 간 모든 위치에서 상호작용 가능계산 복잡도 On² 급증Early Fusion은 강력하지만 비용이 크다3 Hybrid Fusion 현재 주류 구조현재 대부분의 고성능 모델은 완전 Early도 완전 Late도 아니다구조는 보통 다음과 같다 각 모달은 초기에 독립 인코딩 중간 레이어에서 CrossAttention 삽입 최종 단계에서 통합 TransformerCrossAttention의 핵심은Q는 텍스트에서 KV는 이미지에서 가져오는 구조이 말은텍스트 토큰이 이미지 정보를 참조해 의미를 재구성한다는 것이때부터 “교차 추론”이 가능해진다토큰화Tokenization의 문제멀티모달에서 가장 중요한 기술적 이슈 중 하나는 모든 것을 토큰으로 만드는 과정이다텍스트는 원래 토큰 기반이다하지만 이미지는 패치 단위로 잘라야 하고 영상은 시간 단위 프레임으로 나눠야 하며 음성은 스펙트로그램으로 변환해야 한다이 과정에서 정보 손실 발생 해상도 문제 발생 계산량 급증멀티모달 확장의 병목은 사실 토큰화와 시퀀스 길이 문제다멀티모달의 진짜 기술적 난제1 시퀀스 길이 폭발 텍스트 1000 토큰 이미지 패치 576개 영상 프레임 수천 개Transformer은 모달이 늘어날수록 계산 비용은 기하급수적으로 증가한다2 시간적 일관성 유지영상은 단순 이미지 집합이 아니다시간 축을 따라 의미가 변한다문제는현재 모델은 장기 시간 인과 추론에 약하다짧은 클립 요약은 가능하지만 복잡한 상황 전개 이해는 아직 제한적이다3 의미 정렬의 불완전성“강아지”라는 단어와 강아지 이미지는 대체로 정렬된다하지만 추상 개념은자유 책임 의도 위협추상 개념의 모달 간 정렬은 여전히 불완전하다World Model 멀티모달의 다음 단계지금의 멀티모달 모델은 기본적으로 이렇게 동작한다입력 → 표현 정렬 → Attention 기반 통합 → 출력문제는 이것이 반응형 시스템이라는 점이다즉 입력이 있어야 계산이 시작된다 모델 내부에 “세계의 구조”가 명시적으로 존재하지는 않는다1 World Model이란 무엇인가World Model은 단순한 표현 정렬이 아니다세계의 상태state와 상태 전이dynamics를 내부적으로 모델링하는 구조형식적으로는 현재 상태 행동 aₜ → 다음 상태 sₜ₊₁ 을 예측하는 모델이다이 개념은 원래 강화학습RL에서 출발했지만 멀티모달과 결합하면서 의미가 확장된다2 왜 멀티모달에서 World Model이 중요한가현재 멀티모달은 정적 장면 설명은 잘한다 짧은 시간 패턴은 이해한다하지만 장기 상황 전개 인과적 구조 물리적 제약 이해는 약하다World Model은 단순한 “패턴 매칭”을 넘어서시간을 따라 세계가 어떻게 변하는지를 학습한다Unified Token Architecture1 모든 것을 토큰으로현재 대부분의 멀티모달 모델은 모달마다 다른 인코더를 쓴다Unified Token Architecture는 다르게 접근한다모든 입력을 동일한 토큰 형식으로 변환하고 단일 Transformer로 처리한다 텍스트 토큰 이미지 패치 토큰 오디오 프레임 토큰 영상 스페이스타임 토큰모두 같은 형식의 “token”으로 취급한다2 장점구조 단순화확장성 증가모달 추가 용이즉새로운 감각이 추가되어도같은 계산 구조 안에 넣을 수 있다3 기술적 난제하지만 문제가 있다① 토큰 폭발영상은 수천 개의 토큰을 만든다 스케일링이 어렵다② 정보 밀도 차이텍스트 토큰 하나와 이미지 패치 하나는 정보량이 다르다같은 토큰으로 취급하는 것이 항상 최적은 아니다③ 동적 해상도 문제영상·이미지는 공간시간 해상도 선택이 중요하다모든 것을 균일 토큰으로 만들면 정보 손실과 계산 부담 사이에서 타협이 필요하다결론 구조적 진화의 현재 위치멀티모달 AI는 단순히 “입력이 늘어난 AI”가 아니다정확히 말하면이질적 신호를 공통 표현 공간으로 압축하고Attention 메커니즘을 통해 상호 참조하도록 만든 계산 구조다현재 멀티모달 AI는1 표현 정렬은 안정화되었고2 교차 Attention 기반 추론은 가능하며3 생성 모델과 통합되었다그러나1 물리적 세계 모델은 아직 불완전하며2 장기 인과 추론은 제한적이고3 계산 비용은 여전히 가장 큰 병목이다

포스트 양자 시대의 보안 : 암호화
양자컴퓨터가 던지는 경고오늘날 우리의 금융거래 기업 데이터 의료 기록 심지어 일상적인 메시지까지도 암호화 기술에 의해 보호되고 있다 하지만 이 견고한 방패가 가까운 미래에 무너질 수 있다는 우려가 있다 바로 양자컴퓨터Quantum Computer 때문이다양자컴퓨터는 기존 슈퍼컴퓨터로 수십억 년이 걸릴 문제를 몇 분 만에 풀어낼 수 있는 잠재력을 가지고 있다 특히 현재 가장 많이 쓰이는 RSA ECC 같은 암호 알고리즘을 단숨에 깨뜨릴 수 있다는 점이 문제다 이 때문에 전 세계 기업과 정부는 ‘포스트양자 암호PostQuantum Cryptography PQC’를 필수 전략으로 삼고 있다요즘 유튜브나 레딧 같은 커뮤니티를 보면 “양자컴퓨터가 나오면 내 비트코인은 안전할까” 같은 질문이 폭발적으로 올라오고 있다 이처럼 보안 위협에 대한 대중적 관심도 커지고 있으며 이는 단순한 IT 이슈를 넘어 경제·비즈니스 전체에 영향을 주는 흐름이다양자컴퓨터와 암호의 위기현대 암호화의 핵심은 어려운 수학 문제를 빠르게 풀 수 없다는 가정에 기반한다 예를 들어 RSA는 큰 수를 소인수분해하는 것이 어렵다는 점을 이용한다 하지만 양자컴퓨터는 쇼어 알고리즘Shor’s Algorithm을 통해 이 문제를 효율적으로 해결할 수 있다 RSA 2048비트 → 고전적 슈퍼컴퓨터 수십억 년 RSA 2048비트 → 양자컴퓨터충분히 큼 수 시간 또는 그 이하이 차이는 충격적이다 만약 충분히 강력한 양자컴퓨터가 등장하면 전 세계 인터넷 보안 인프라가 순식간에 무력화될 수 있다포스트양자 암호PQC의 대두이에 대응하기 위해 학계와 산업계는 새로운 암호 체계를 개발하고 있다 이를 포스트양자 암호PQC라고 부른다 특징은 다음과 같다 수학적 기반 전환 기존 소인수분해나 이산대수 문제 대신 격자 문제Lattice Problem나 해시 기반 구조를 사용한다 양자 내성Quantumresistant 양자컴퓨터가 등장해도 풀기 어려운 문제를 기반으로 설계된다 표준화 노력 미국 국립표준기술연구소NIST는 2016년부터 PQC 표준화를 추진 중이며 2024년 1차 알고리즘 선정이 이루어졌다기업들은 이미 이 움직임에 대응 중이다 구글은 크롬 브라우저에 PQC 알고리즘을 시험 적용했고 IBM과 마이크로소프트는 클라우드 서비스 보안 체계에 PQC 도입을 준비 중이다새로운 암호방식 격자 문제Lattice Problems 격자 기반 암호는 유클리드 공간에 있는 점들의 격자 구조lattice에서 특정 계산이 얼마나 어려운지에 의존합니다 대표적인 문제들은 다음과 같습니다1 SVP Shortest Vector Problem 최단 벡터 문제정의 주어진 격자 안에서 가장 짧은 벡터를 찾는 문제직관적으로는 바둑판 같은 격자 위에 점들이 퍼져 있는데 원점에서 시작해 격자를 따라갈 때 가장 가까운 점을 찾는 것이 매우 어렵다는 것난이도 일반 컴퓨터는 물론 양자컴퓨터도 효율적으로 풀기 어렵다고 알려져 있음2 CVP Closest Vector Problem 근접 벡터 문제정의 격자 밖의 임의의 점이 주어졌을 때 그 점과 가장 가까운 격자 점을 찾는 문제비유 지도 위 특정 위치에서 “가장 가까운 기차역격자점”을 찾는 문제와 유사하지만 차원이 수백 이상으로 올라가면 계산이 폭발적으로 어려워짐3 LWE Learning With Errors 오차 학습 문제정의 어떤 선형 방정식이 약간의 노이즈오차가 섞여 주어진 경우 원래의 해를 찾아내는 문제특징 격자 문제와 수학적으로 연결되며 실제 PQC 알고리즘의 핵심 기반으로 가장 많이 쓰임예 “5x ≈ 14 mod 23” 같은 방정식이 오차와 함께 여러 개 주어졌을 때 원래 x 값을 추론하는 것이 어렵다5 RingLWE ModuleLWELWE 문제를 더 효율적이고 빠르게 만든 변형 실제 암호 알고리즘예 Kyber Dilithium 등에서 사용비즈니스적 시사점양자 보안은 단순히 기술적인 문제가 아니다 기업 경쟁력 규제 준수 고객 신뢰까지 직결되는 비즈니스 과제다금융권 은행 증권 블록체인 거래소는 암호 체계 전환을 서둘러야 한다 이미 “양자 안전 지갑QuantumSafe Wallet”이라는 개념이 등장하고 있다헬스케어 환자 데이터가 유출될 경우 심각한 사회적 문제가 발생하므로 PQC 적용이 필수적이다정부공공기관 국가 안보 차원에서 PQC 도입은 더 이상 미룰 수 없는 문제다스타트업 보안·클라우드·핀테크 분야 스타트업은 “양자 대비 솔루션”이라는 새로운 시장 기회를 잡을 수 있다레딧의 보안 전문 포럼에서도 최근 “포스트양자 시대에 대비하지 않는 기업은 5년 뒤 생존하기 힘들 것”이라는 토론이 화제가 되었다 이는 전문가뿐만 아니라 업계 전반에 퍼지고 있는 위기의식이다현실과 과장 사이물론 현재의 양자컴퓨터는 아직 수천 수만 개의 안정적인 큐비트를 구현하지 못하고 있다 따라서 내일 당장 인터넷 암호가 무너진다는 시나리오는 과장일 수 있다 하지만 “수십 년 뒤의 위협을 지금 준비해야 한다”는 점이 중요하다NIST의 보고서에 따르면 보안 체계 교체에는 최소 10년 이상이 걸린다 은행·정부기관처럼 레거시 시스템이 많은 조직일수록 더 길다 따라서 아직 양자컴퓨터는 멀었다는 안일함은 위험하다결론 준비하는 자만이 살아남는다포스트양자 암호화는 단순히 보안 업계의 연구 과제가 아니다 모든 기업 모든 산업이 직면한 디지털 신뢰Digital Trust 문제다앞으로 510년 사이에 누가 먼저 안전한 암호 체계를 도입하느냐에 따라 고객 신뢰와 시장 점유율이 갈릴 수 있다2025년 현재 우리는 “양자 위협”을 공포 영화처럼 과장되게 볼 필요는 없다 그러나 대비 없는 낙관은 위험하다 포스트양자 시대의 보안은 위기와 기회가 공존하는 새로운 비즈니스 전환점이 될 것이다

WebGPU 가속화-브라우저가 AI를 품다
이제 AI는 더 이상 서버 전용 기술이 아니다WebGPU 가속화를 통해 브라우저 내에서 AI 모델을 직접 실행할 수 있는 시대가 열렸다이는 클라우드 인프라에 의존하지 않고도 사용자의 로컬 디바이스에서 이미지 생성 LLM 추론 음성 인식 3D 렌더링까지 수행할 수 있음을 의미한다Google Chrome Edge Firefox Safari 등 주요 브라우저가 WebGPU를 공식 지원하기 시작하면서웹 환경이 단순한 콘텐츠 뷰어를 넘어 AI 런타임 플랫폼으로 진화하고 있다WebGPU란1정의WebGPU는 WebGL의 후속으로 브라우저에서 GPU 연산을 직접 수행할 수 있게 하는 차세대 그래픽 및 연산 API다그래픽뿐 아니라 일반적인 병렬 연산General Purpose GPU을 지원하여 AI 추론 과학 계산 신호 처리 등에도 활용된다2 특징 요약기능설명GPU 직접 접근브라우저가 GPU를 직접 제어해 고성능 연산 가능병렬 처리 지원이미지 생성 LLM 추론 3D 렌더링 등 대규모 연산을 빠르게 처리WebAssembly와 호환WASM과 결합해 경량 모델 실행 가능크로스 플랫폼Windows macOS Linux Android iOS 브라우저 지원3 브라우저 내 AI 실행의 의미항목효과실시간 처리클라우드 요청 없이 즉시 결과 생성오프라인 가능성로컬 디바이스만으로 AI 실행개인정보 보호데이터가 외부 서버로 전송되지 않음설치 불필요별도 앱 설치 없이 URL만으로 AI 서비스 이용 가능즉 WebGPU는 브라우저가 곧 AI 런타임이 되는 기반 기술이다기술적 기반1 WebGPU WebAssembly WASMAI 모델을 웹에서 실행하려면 JS만으로는 느리기 때문에 WebAssembly를 통해 네이티브급 속도의 연산을 수행한다WebGPU WASM 조합은 아래와 같은 구조로 작동한다사용자 입력 → WASM 모듈 → WebGPU 커널 실행 → 결과 렌더링2 경량 AI 모델예 ONNX Runtime Web TensorFlowjs with WebGPU backend Transformersjs HuggingFace이들 프레임워크는 WebGPU를 활용해 브라우저 내에서텍스트 요약 음성 인식 이미지 분류 LLM 응답 등을 수행한다3 WebGPU 코드 예시 WebGPU 디바이스 초기화 예시 async function initWebGPU if navigatorgpu throw new ErrorWebGPU not supported on this browser const adapter await navigatorgpurequestAdapter const device await adapterrequestDevice consolelogWebGPU initialized device return device 이 디바이스 객체를 통해 텍스처 생성 연산 셰이더 실행 모델 추론이 가능하다브라우저 GPU써봤자 성능 안나오지 않나 왜 이게 의미가 있나“일반 PC의 GPU로도 AI를 ‘돌릴 수는 있지만’ 대형 모델을 ‘빠르게’ 돌리긴 어렵다”즉 클라우드 대체는 아니고 경량화된 AI 추론용으로 진화하고 있는 기술입니다1 성능 측면 로컬 GPU vs 클라우드 GPU항목로컬 WebGPU 예 RTX 4060 M2 GPU 등클라우드 GPU A100 H100 등GPU 메모리824GB 수준4080GB 이상연산 성능약 1040 TFLOPS약 1501000 TFLOPS모델 크기 한계최대 7B 모델 이하 경량화 필요70B300B 모델 가능응답 속도빠름 로컬 IO네트워크 지연 존재배포 용이성설치 불필요 웹에서 즉시 실행서버 설정 필요2 실제로 가능한 모델 수준현재 WebGPU로 실행 가능한 AI 모델들은 아래와 같아요모델명용도특징Phi3 mini 38B텍스트 생성로컬 LLM 중 속도품질 균형 우수Stable Diffusion Turbo SDXL Lite이미지 생성12초 내 로컬 생성 가능Whisper tiny small음성 인식브라우저 내 STT 가능CLIP ViTB32이미지텍스트 임베딩WebGPU 기반 검색분류에 활용예를 들어 Chrome Canary나 Edge Dev에서Transformersjs WebGPU backend로 Phi3mini를 돌리면 맥북 M2에서도 초당 35토큰 정도 생성됩니다 대형 모델은 불가능하지만 실시간 챗봇에는 충분한 속도3 아키텍처의 변화 를 주도한다기존WebGPU 기반모델은 서버에서 돌림모델이 로컬에서 돌 수 있음데이터는 서버로 전송됨데이터가 사용자 디바이스에 머무름서버비용 발생클라우드 인프라 불필요네트워크 지연 존재즉시 실행 가능즉보안 강화 개인 데이터 외부 전송 없음비용 절감 서버 운영 불필요반응속도 개선 지연 거의 없음이라는 세 가지 큰 장점이 생깁니다 이건 “속도의 절대값”보다는 “경험의 질”을 바꿔주는 변화예요실제 적용 사례41 브라우저 기반 AI 툴Figma AI Canva AI 디자인 자동 생성 및 수정 시 WebGPU를 활용Runway Stability AI 이미지·영상 생성용 경량 모델 브라우저 실행42 실시간 3D XR 콘텐츠WebGPU로 렌더링된 3D 오브젝트 위에 AI 기반 인터랙션을 추가ARVR 시뮬레이션을 실시간으로 처리할 수 있다예사용자가 브라우저에서 직접 3D 아바타 생성 음성 대화형 AI 인터랙션을 실행43 브라우저 내 LLMTransformersjs 기반의 bert gpt 모델 브라우저 실행Chrome Canary에서 Llama 3 8B를 로컬 WebGPU로 실행한 데모도 등장최신 트렌드트렌드설명WebGPU AI 도구 확산Stability AI HuggingFace 등에서 WebGPU 백엔드 지원실시간 이미지영상 처리Stable Diffusion ControlNet 브라우저 실행경량 LLM 실행Phi3 TinyLlama Mistral 모델 WebGPU 추론멀티모달 지원텍스트 이미지 오디오 통합 AI하이브리드 처리로컬WebGPU 클라우드고성능 연산 혼합 구조 주의사항GPU 성능에 따라 추론 속도 격차 존재Safari 등 일부 브라우저는 WebGPU 제한적 지원대규모 LLM70B↑은 여전히 클라우드 필요브라우저 보안 모델에 따른 GPU 샌드박싱 이슈 고려 필요WebGPU는 웹을 AI 플랫폼으로 전환시키는 핵심 기술이다앞으로는 Stable Diffusion LLaMA SpeechtoText 3D Simulation까지 브라우저 내에서 실시간으로 구동될 수 있을 것이다💡 “웹페이지 하나가 곧 AI 애플리케이션이 된다”WebGPU는 단순한 그래픽 API를 넘어 차세대 온디바이스 AI 시대의 핵심 인프라로 자리 잡고 있다
AI 에이전트 구조 이해 및 구체적인 설계 방법
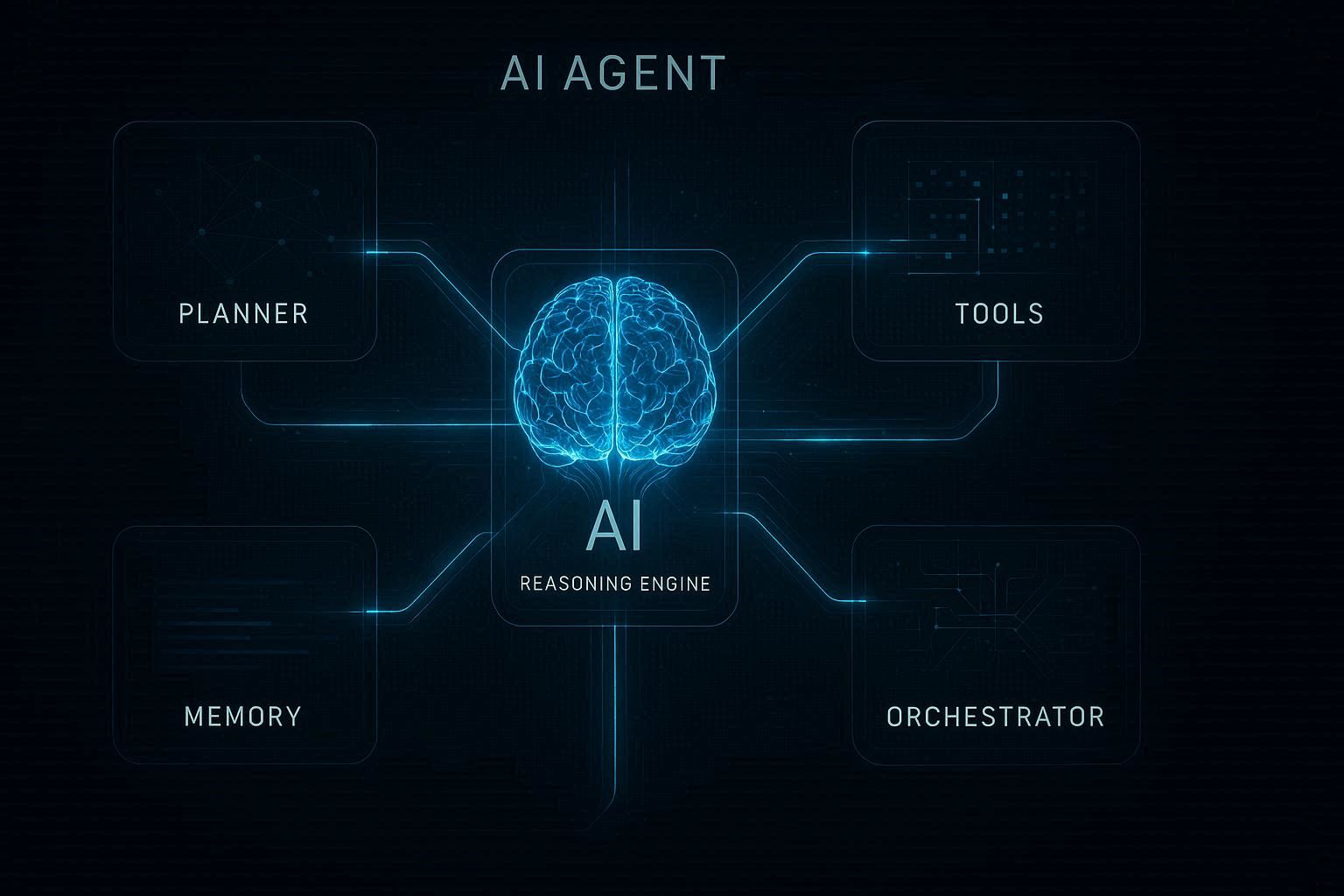
실제 제품을 만드는 관점에서 LLM은 ‘두뇌’일 뿐이다AI 제품을 만들 때 가장 흔한 착각이 있다“LLM API 붙이면 된다”하지만 실제 제품을 만들면 금방 깨닫는다 LLM은 생각은 할 수 있지만 행동은 못한다예를 들어 사용자가 이렇게 말한다“출장 일정 만들어줘”LLM은 텍스트를 생성할 수는 있지만 다음 작업을 수행하지 못한다 항공편 검색 호텔 가격 비교 일정 생성 캘린더 등록즉 LLM은 추론 엔진일 뿐이다실제 제품을 만들려면 행동을 수행하는 시스템이 필요하다 이 구조가 바로 AI Agent Architecture다실제 Agent 아키텍처실제 서비스에서 가장 기본적인 Agent 구조는 다음과 같다User ↓ Orchestrator ↓ LLM Reasoning ↓ Tool Router ↓ External Tools ↓ Memory각 컴포넌트는 명확한 역할을 가진다1 Orchestrator전체 에이전트 실행을 관리하는 레이어다예를 들어 요청 분석 실행 루프 관리 tool 호출 제어보통 다음 형태로 구현한다Python Agent loop LangGraph Temporal workflow이 루프가 Agent 실행 엔진이다2 Planner 구현Planner는 목표를 작업 단계로 분해한다예를 들어 사용자 요청가 아래와 같다면출장 일정 만들어줘Planner 출력1 항공편 검색 2 호텔 검색 3 일정 생성Planner는 보통 LLM prompt로 구현한다예You are a planning AI Break the user request into steps Return JSON User request 출장 일정 만들어줘출력 steps search flight search hotel create itinerary 이 결과가 Agent 실행의 작업 큐가 된다3 Tool Layer 설계Agent 시스템에서 가장 중요한 부분이 Tool Layer다Tool은 AI가 사용할 수 있는 실제 기능이다예searchflight searchhotel createcalendarevent sendemail보통 Tool은 다음 형태로 정의한다class Tool name searchflight description Search flight tickets def runself query return flightapiquery그리고 LLM이 tool을 선택하게 한다예Available tools searchflight searchhotel createcalendareventLLM 출력 toolsearchflight arguments fromSeoul toTokyo 이 구조가 Function calling Tool calling이다4 Agent 실행 루프Agent는 보통 loop 구조로 동작한다1 user request 2 plan 생성 3 tool 선택 4 tool 실행 5 결과 평가 6 다음 행동 결정이 loop가 Agent reasoning cycle이다5 Memory 설계Memory는 보통 3개 레이어로 나뉜다1 shortterm memory현재 작업 contextconversation history current task tool results보통은context window로 관리한다2 longterm memory사용자 정보와 했던 정보를 압축하여 저장한다이는 정보자체를 압축하여 저장하거나 별도 db를 만들어서 저장하는것이 좋다예user preferences previous tasks history보통vector DB를 사용한다예PineconeWeaviatepgvector3 working memoryAgent 작업 상태예current plan task state intermediate results이건 보통 메모리 기반 Redis나 state store에 저장한다실제 Agent 아키텍처 현업 구조실제 서비스는 보통 이렇게 생긴다Frontend ↓ API Gateway ↓ Agent Service ↓ LLM Service ↓ Tool Service ↓ External APIs ↓ Memory Store예Nextjs FastAPI Agent OpenAI API Redis memory Postgres External toolsAgent 시스템의 진짜 어려운 부분많은 사람들이 Agent 구현을 어렵게 생각하지만 진짜 어려운 부분은 따로 있다1 tool reliabilityAI가 tool을 잘못 호출한다2 hallucination없는 API를 호출한다3 loop 문제Agent가 무한 루프에 빠진다4 cost 문제tool LLM 호출이 많아진다그래서 실제 서비스에서는 다음을 추가한다 tool validation step limit cost guardrail fallback logic정리AI Agent는 단순한 개념이 아니다 실제 시스템으로 보면 다음 구조다LLM → reasoning Planner → task decomposition Tools → action Memory → context Orchestrator → execution loop이 다섯 가지가 결합되어야 실제로 일을 수행하는 AI 시스템이 만들어진다2편 httpsletsplmequest2355shortcut3편 httpsletsplmequest2356shortcut

