
RAG는 새로운 검색엔진의 왕으로 등극하나? | 매거진에 참여하세요
RAG는 새로운 검색엔진의 왕으로 등극하나?
#검색 #질의 #의도 #벡터 #rag #db #리서치 #ai




검색은 끝났고, 리서치가 시작되었다
검색창에 단어를 넣고 결과를 뒤져보는 일,
우리는 이 행위를 너무 당연하게 받아들이며 살아왔다.
그러나 2024년 후반부터 등장한 GPT-4o, Perplexity, 그리고 각종 벡터 검색 기반의 RAG 서비스들은 이 당연함을 흔들고 있다.
단순히 결과를 “찾는” 것을 넘어, 내가 어떤 정보를 왜 찾는지까지 파악해서 직접 만들어주는 검색.
이제 검색은 '찾기'가 아니라 '조립하기'로 변하고 있다.
여기서 중심에 선 기술이 바로 RAG (Retrieval-Augmented Generation)이다.
그리고 RAG의 심장에는 벡터 데이터베이스가 있다.
왜 기존 검색은 한계에 부딪혔는가
우리가 구글 검색창에 넣는 키워드는 단어의 "정확한 일치"를 기반으로 작동한다.
이른바 인덱싱된 문서들과의 토큰 매칭, 그리고 Pagerank 기반의 랭킹 시스템이다.
하지만 문제는 이 방식이 맥락(context)에는 약하다는 점이다.
“예비창업자에게 좋은 세금 정보”를 검색하면,
“예비창업자”라는 키워드가 들어간 세금 기사만 보여줄 뿐,
실제로 그들에게 적합한 절세 전략이나, 정부 지원 정책은 잘 연결해주지 않는다.
왜냐하면, 검색엔진은 문장 전체의 의미를 이해하지 못하기 때문이다.
RAG의 등장: 의미 기반 검색의 시작
RAG는 말 그대로 “검색(Retrieval)”을 “생성(Generation)”에 붙여주는 구조다.
GPT처럼 거대한 언어모델에게, 우리가 필요로 하는 정보들을 미리 찾아서 넣어주는 방식이다.
구조는 간단하다:
1. 사용자 질문을 벡터화 → 고차원 의미 공간으로 변환
2. 벡터 DB에서 유사한 문서 추출 → 의미 기반으로 유사도 측정
3. LLM에 함께 넣어서 답변 생성 → "찾은 것 + 생성"의 하이브리드
이 과정을 통해,
GPT는 “검색한 사실”을 기반으로, “잘 정리된 요약”을 제공하게 된다.
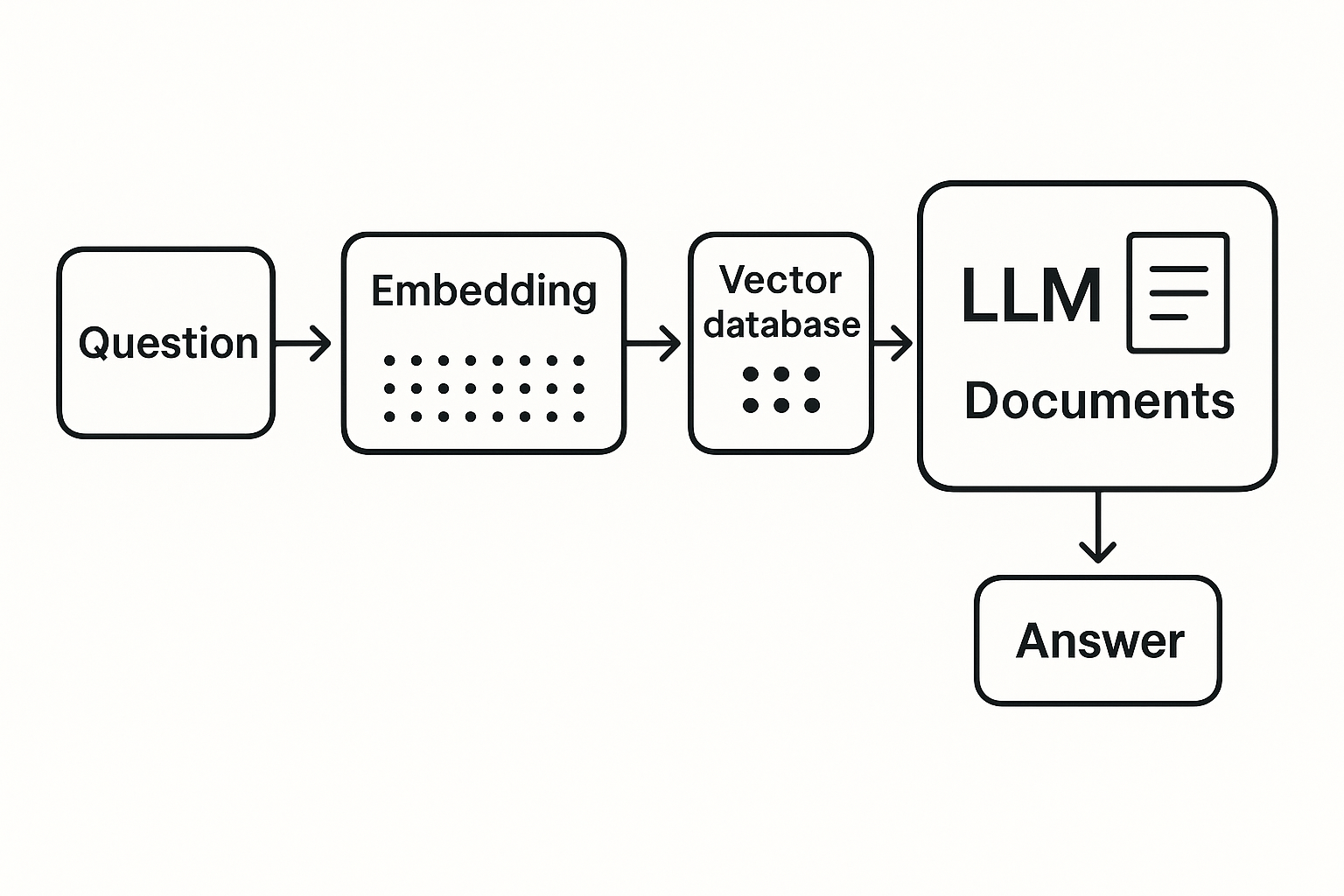
벡터 DB가 핵심이다: Pinecone, Weaviate, Qdrant, Chroma
이 RAG의 근간에는 벡터 DB가 존재한다.
기존 SQL이나 NoSQL DB는 단어를 비교하지만, 벡터 DB는 문장의 의미를 1,536차원 벡터로 저장하고 비교한다.
주요 벡터 DB 비교:
제품 | 특징 | 오픈소스 여부 | 기업 활용 예 |
|---|---|---|---|
Pinecone | 서버리스, LLM 최적화 | ❌ | Notion, Perplexity |
Weaviate | Graph+벡터 검색 결합 | ✅ | Recraft, open-LLM 검색 |
Qdrant | 고속 추론 성능, Rust 기반 | ✅ | SaaS 검색 내장형 |
Chroma | LangChain 기본 벡터엔진 | ✅ | 사이드 프로젝트 용도 많음 |
성능의 차이는 존재하지만, 핵심은 "어떻게 쿼리하느냐"다.
유저의 질문을 벡터화하는 방식, 임베딩 모델의 종류, 필터링 기준이 UX 전체를 좌우한다.
Perplexity, ChatGPT, You.com – RAG의 UI는 무엇이 다른가
2024년 후반 이후 등장한 AI 검색 서비스들은
기존의 검색창 UI를 유지하면서도, 결과 방식에서 큰 차이를 보인다.
예: Perplexity
- 사용자가 묻는 순간 바로 RAG 실행
- 검색된 문서를 "참조 링크"로 명시
- 답변 내에 하이라이트된 출처가 연결됨
→ 신뢰 가능한 리서치 경험 제공
예: ChatGPT + 웹브라우징
- GPT가 수십 개 문서를 요약/조립
- 사용자는 실제로 "웹 탐색"을 생략함
→ 탐색보다 '요약' 중심 UX
RAG 기반 UX에서 중요한 3가지 요소
RAG가 UX 관점에서 기존 검색과 완전히 달라지는 지점은 다음 3가지다:
"무엇을 봤는지"를 보여줘야 한다
→ GPT가 어떤 문서를 참조했는지 명시해야 사용자가 안심함"근거 있는 말"만 해야 한다
→ 허위 생성 방지를 위해 Reference Linking이 필수"사용자 쿼리 의도"를 적극 해석해야 한다
→ 단어가 아니라 목적을 기반으로 문서 검색이 이뤄짐
검색은 사라지고, "정보 요약"이 UX가 된다
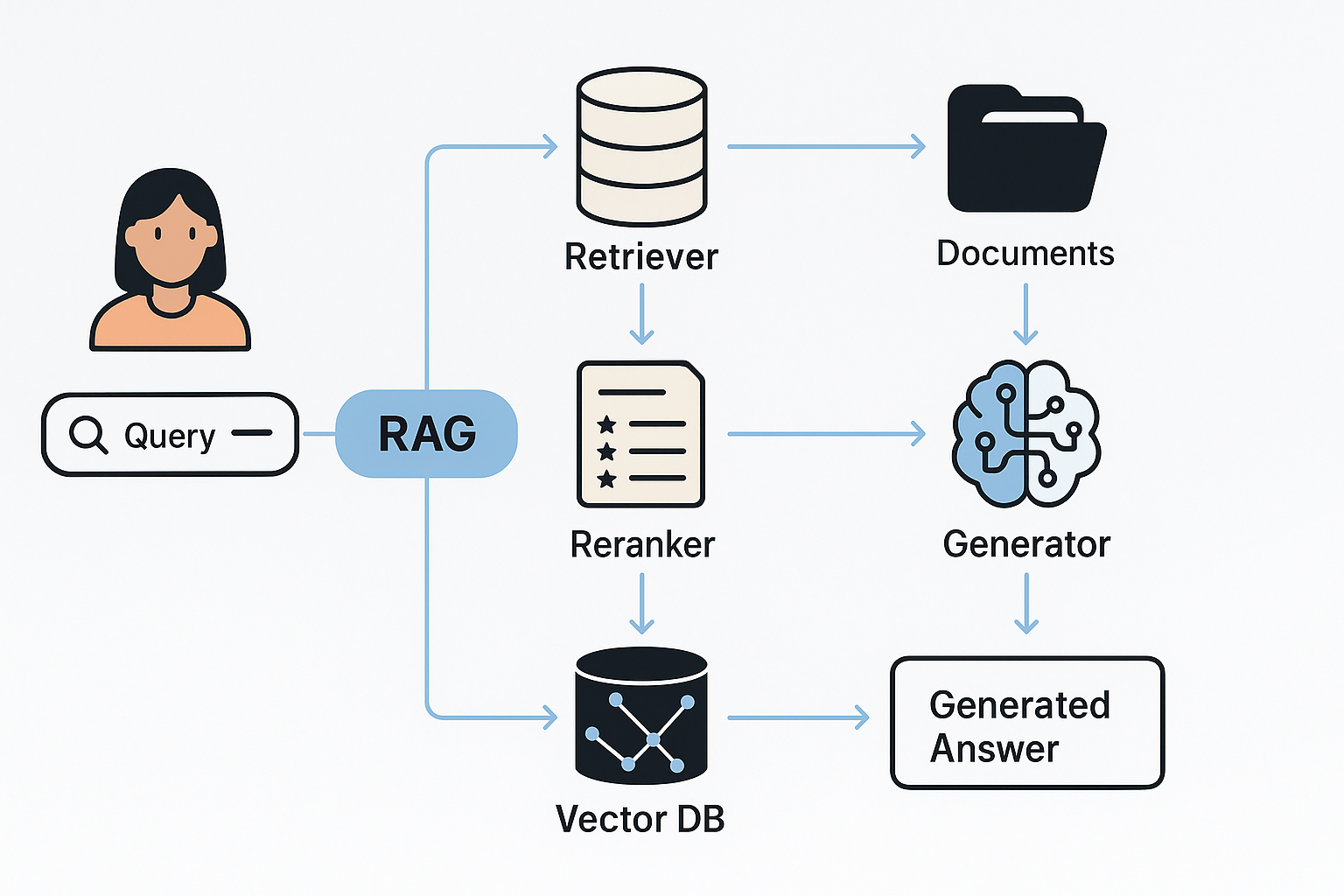
결국 우리는 점점 검색 결과를 직접 탐색하는 것이 아니라,
“요약된 내용을 기반으로 다시 질문하는” 구조로 이동 중이다.
이런 의미에서, 검색은 점점 "사용자의 질문을 더 잘 다듬어주는 UI"가 되고 있다.
질문 → 요약 → 다시 질문 → 더 정제된 요약
이 과정을 반복하며, 사용자는 원하는 결과에 도달한다.
이건 구글이 해왔던 패턴과는 전혀 다르다.
링크의 바다에서 고르는 게 아니라, 답변을 받아들이는 경험에 가깝다.
"RAG는 검색이 아니다, 리서치다"
지금 이 글을 읽는 당신이, 어떤 문장을 기억한다면 이것이었으면 한다.
"RAG는 검색(Search)이 아니라 리서치(Research)다."
앞으로 우리가 질문을 던질 때, 그에 대한 '정보를 어떻게 조합해주는가'가 검색의 본질이 될 것이다.
그리고 그 중심엔, GPT가 아닌 벡터 DB가 있을 것이다.
Do you want to find out research service based on rag?
Refer to bunzee.ai

- link_kakaolink_kakao_url
- link_operatorlink_operator_url
- link_investhelp@letspl.me
- link_ad_urllink_ad
